mpreet
Member
- Downloaded
- 11.1 GB
- Uploaded
- 10.9 GB
- Ratio
- 0.98
- Seedbonus
- 167
- Upload Count
- 0 (0)
Member for 7 years

Description 📝
Ollama is an AI tool that allows you to run large language models, like Llama 2, locally on your own computer instead of relying on cloud-based services. This gives you more control and privacy, as well as the ability to customize and create your own models. Ollama is designed to be user-friendly, so it's suitable for both AI professionals and enthusiasts who want to explore natural language processing. Some key features include local execution for faster processing, support for advanced models like Llama 3, Mistral, Gemma and model customization options.
🌃 Features
- Local execution: Ollama allows you to run language models locally on your own computer, giving you more control and privacy compared to cloud-based services.
- Advanced model support: Ollama supports advanced language models like Llama 3, Mistral, Gemma and lot more enabling you to perform various natural language processing tasks.
- User-friendly interface: Ollama is designed to be user-friendly, making it accessible for both AI professionals and enthusiasts who want to explore language models.
- Customization options: With Ollama, you can customize and create your own models, giving you the flexibility to tailor language models to your specific needs.
- Cross-platform support: Ollama is currently available for macOS, with support for Windows and Linux, allowing you to run language models on various platforms.
- Regular updates: The Ollama team actively maintains and updates the tool, ensuring that users have access to the latest features and improvements.
- Seamless integration: Ollama allows for seamless integration with various applications and systems, enabling you to incorporate language models into your projects with ease for example VSCode integration using Llama coder extension.
- Community engagement: Ollama fosters a community of developers, researchers, and enthusiasts who share knowledge, collaborate, and contribute to the tool's development, making it a valuable resource for anyone interested in language models.
- No need to be always online as it works fully offline once fully setup.
System Requirements 🖥️
- Operating System: macOS, Windows, or Linux (note that Windows and Linux support are still in development).
- Hardware: A modern computer with a dedicated graphics card (GPU) is recommended. For smaller models, a CPU with at least 8 cores and 16 GB of RAM might be sufficient, but for larger models like Llama 2, a GPU with at least 8 GB of VRAM is strongly recommended for optimal performance.
Ollama supports a list of models available on
Here are some example models that can be downloaded/run using command line:
You must be registered for see links
Here are some example models that can be downloaded/run using command line:
| Model Name | Parameters | Model Size | run command |
|---|---|---|---|
| Llama 3 | 8Billion | 4.7GB | ollama run llama3 |
| Llama 3 | 70Billion | 40GB | ollama run llama3:70b |
| Mistral | 7Billion | 4.1GB | ollama run mistral |
| Dolphin Phi | 2.7Billion | 1.6GB | ollama run dolphin-phi |
| Phi-2 | 2.7Billion | 1.7GB | ollama run phi |
| Neural Chat | 7Billion | 4.1GB | ollama run neural-chat |
| Starling | 7Billion | 4.1GB | ollama run starling-lm |
| Code Llama | 7Billion | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7Billion | 3.8GB | ollama run llama2-uncensored |
| Llama 2 13B | 13Billion | 7.3GB | ollama run llama2:13b |
| Llama 2 70B | 70Billion | 39GB | ollama run llama2:70b |
| Orca Mini | 3Billion | 1.9GB | ollama run orca-mini |
| LLaVA | 7Billion | 4.5GB | ollama run llava |
| Gemma | 2Billion | 1.4GB | ollama run gemma:2b |
| Gemma | 7Billion | 4.8GB | ollama run gemma:7b |
| Solar | 10.7Billion | 6.1GB | ollama run solar |
Note: You should have at least 8 GB of RAM available to run the 7Billion model, 16 GB to run the 13Billion model, and 32 GB to run the 33Billion model.
A good GPU combination improves output performance drastically.
Downloading AI models requires an active internet connection. after download completes then you can run it fully offline.
Screenshots 📸
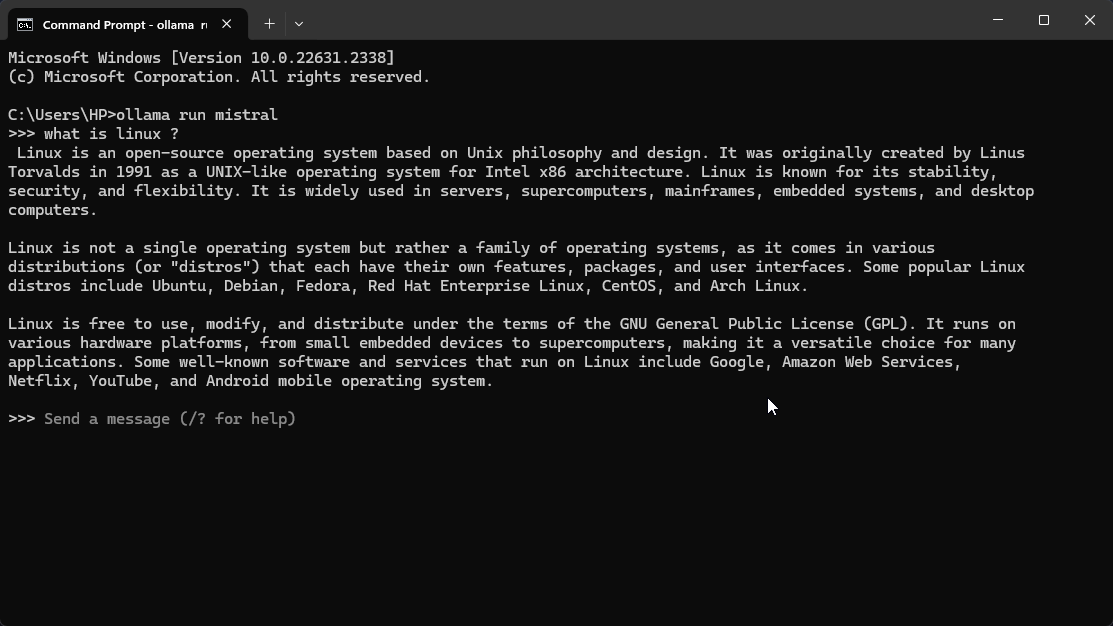
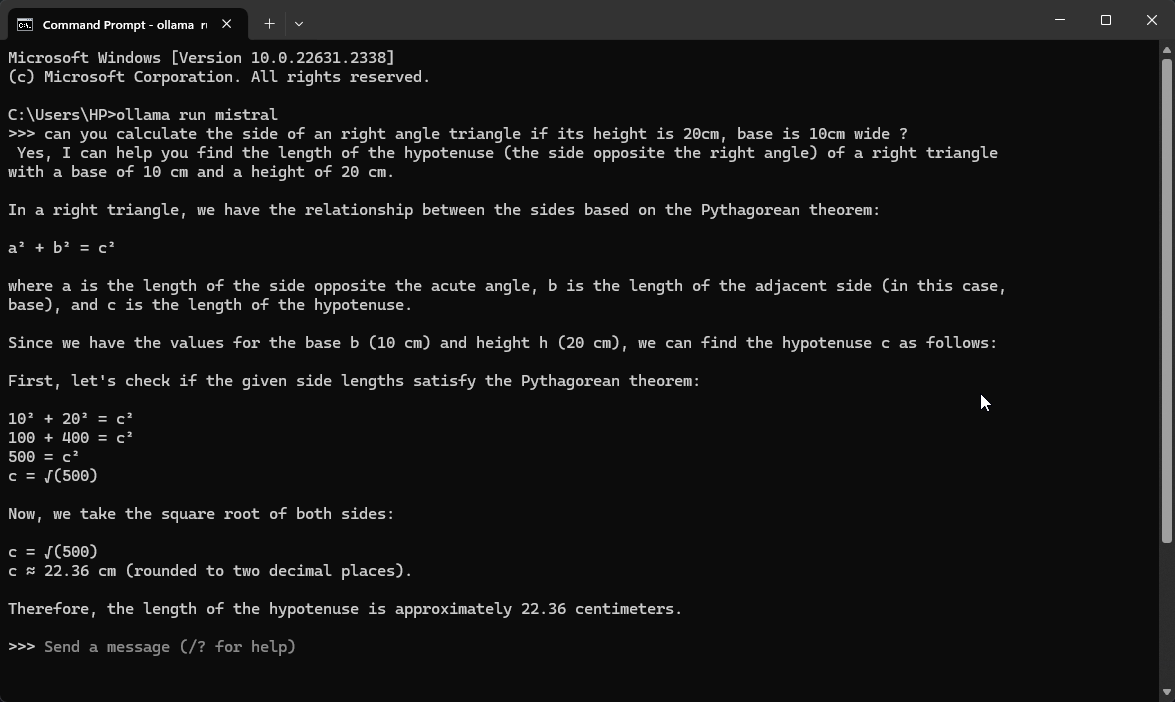
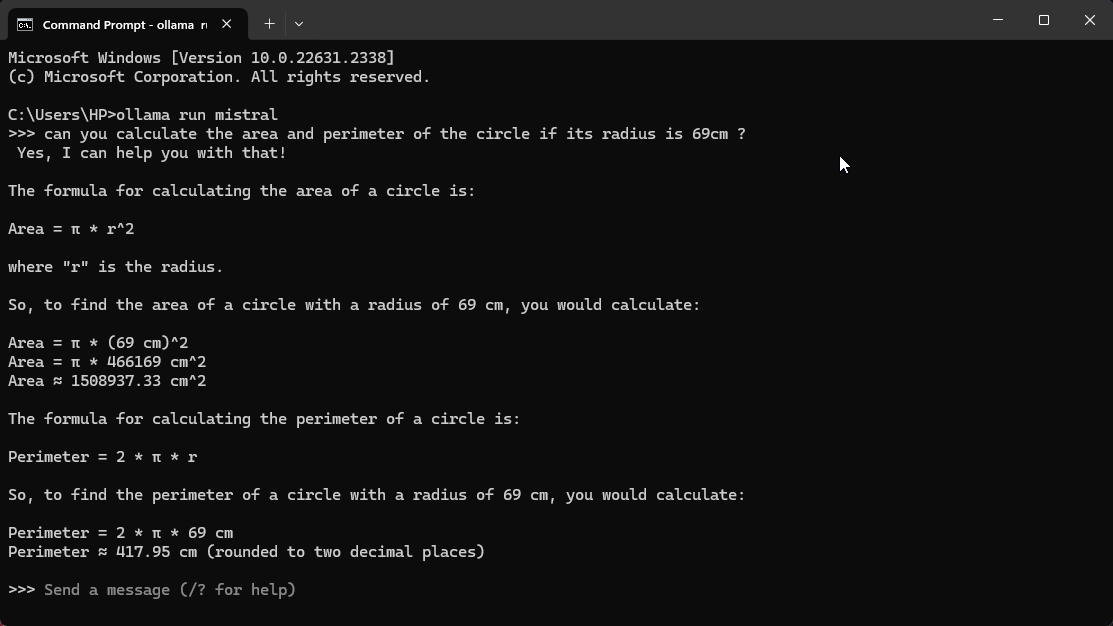
Installation Instructions ⬇️
Download provided zip file, Extract it & install according to your OS type.
Post installation you can run model in CLI using ollama run <modelname> for example: ollama run mistral

Installation Instructions ⬇️
Download provided zip file, Extract it & install according to your OS type.
Post installation you can run model in CLI using ollama run <modelname> for example: ollama run mistral
🦠🛡️ VirusTotal Results:
⬇️Download Links⬇️
You must be registered for see links
⬇️Download Links⬇️
You must be registered for see links
")